LLMによるポケモンバトルでの人間並みのパフォーマンス達成
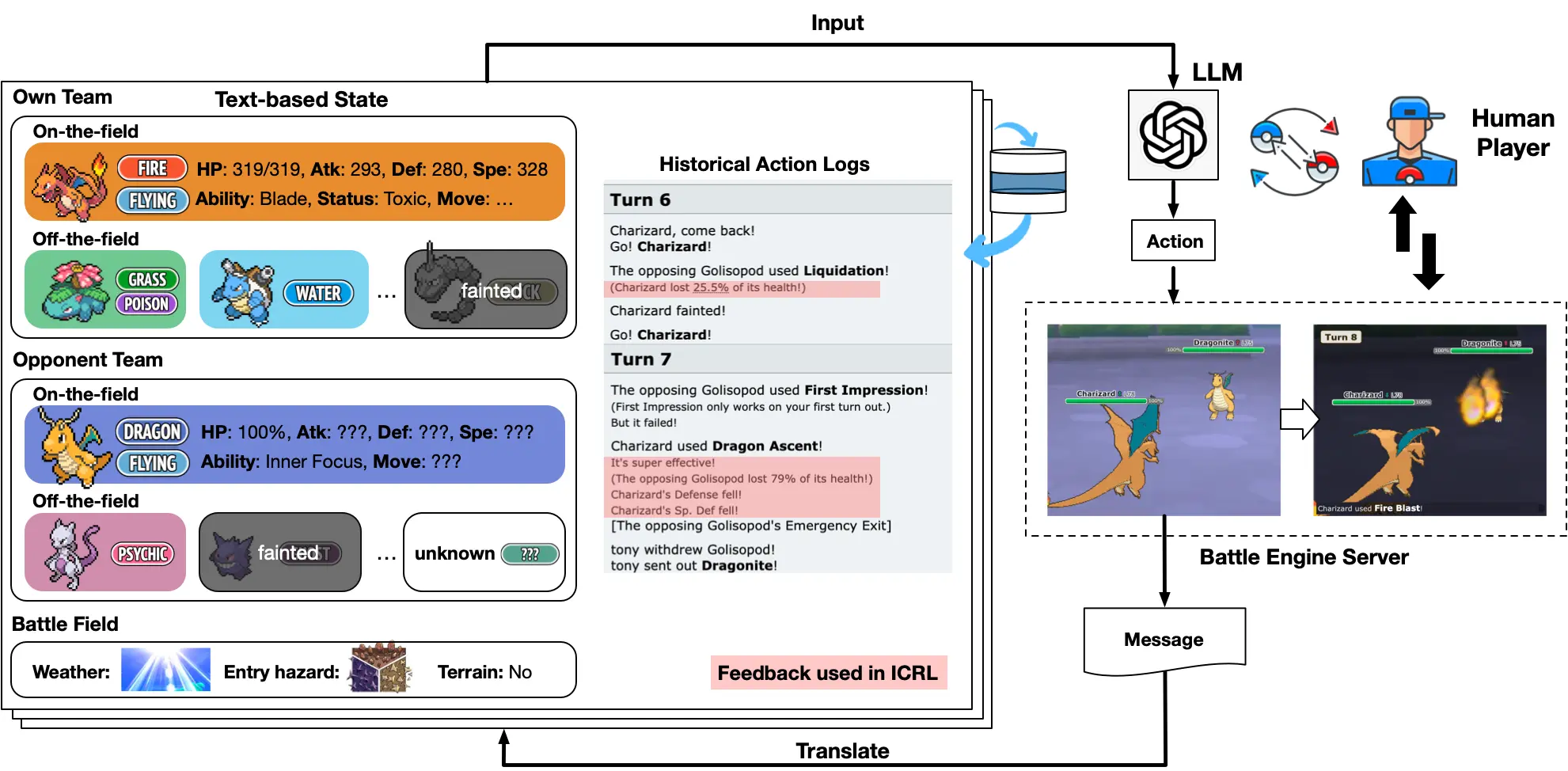
ポケモンバトルにおいて人間と同等のパフォーマンスを実現したエージェント、POKELLMON の紹介です。この研究は、テキストベースのフィードバックを用いたコンテキスト内強化学習、外部知識を使用した幻覚対策の知識拡張生成、強力な対戦相手に対するパニックスイッチングを避ける一貫性のあるアクション生成、という3つの戦略を組み合わせることで、人間のような戦略的能力を実現しました。

主な成果
- オンラインバトルでの実績: POKELLMONは、ネット上で公開している非公式の対戦シミュレーター「Pokemon Showdown」を使って、競争で 49 %、招待戦では 56% の勝率を達成しました。
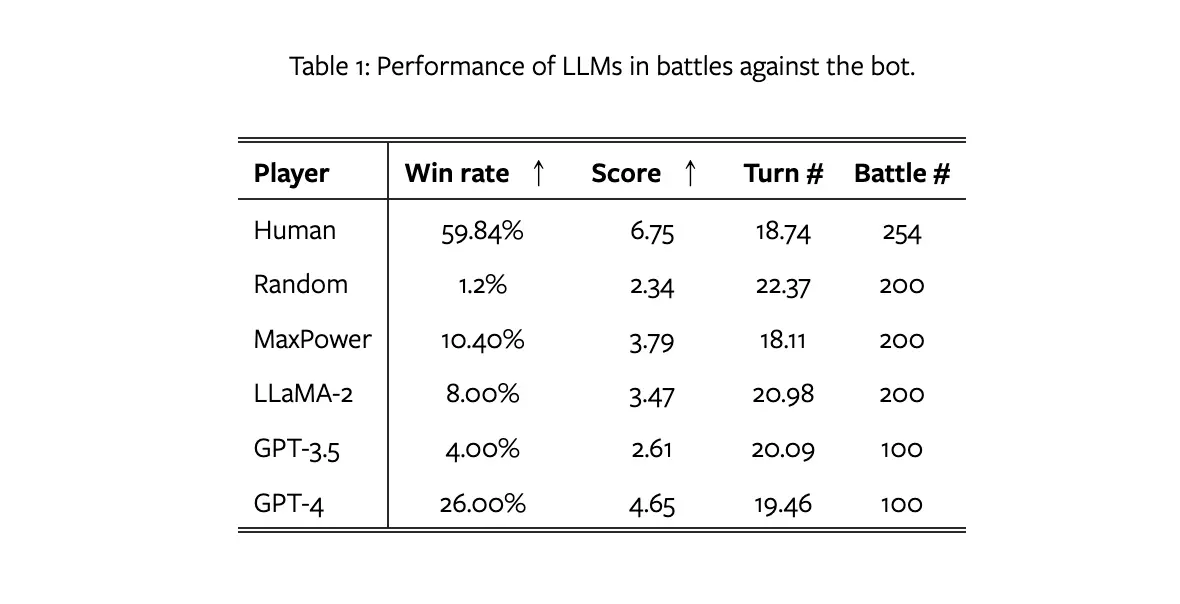
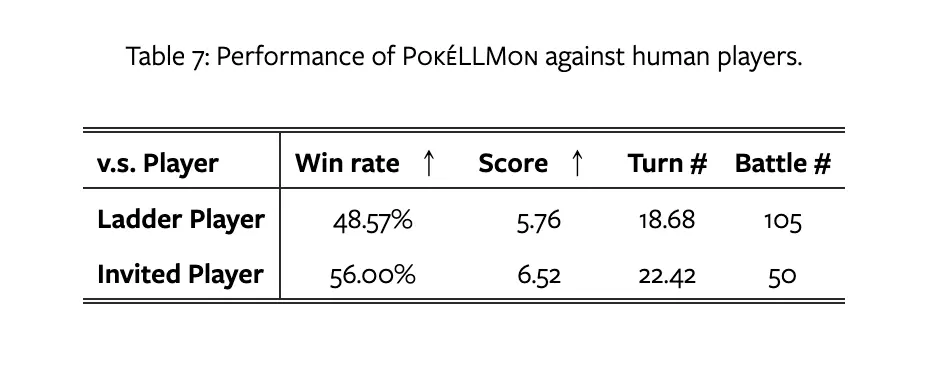
- 戦略的能力: このエージェントは、ポケモンバトルの戦術的なゲームにおいて、人間らしい戦略を実行する能力を示しています。
技術的アプローチ
- コンテキスト内強化学習: テキストベースのフィードバックを活用し、ポリシーを洗練させます。
- 知識拡張生成: 外部の知識を組み込むことで、生成時の幻覚を防ぎます。
- 一貫性のあるアクション生成: 強力な対戦相手に対しても、パニックに陥ることなく一貫した行動を取ることができます。
今後の展望
POKELLMON の成功は、大規模言語モデル(LLM)を戦術的バトルゲームに応用する可能性を示しています。また、LLM における幻覚や一貫性のないアクション生成といった課題への取り組みに対する洞察も提供しています。
この技術的進歩は、AI の戦略的思考能力の発展において、重要な一歩を示しています。
元論文:PokéLLMon: A Human-Parity Agent for Pokémon Battles with Large Language Models
Github: https://github.com/git-disl/PokeLLMon?tab=readme-ov-file